9.4 Explore data from MovieLense
dim(MovieLense@data)## [1] 943 1664MovieLense has ratings by 943 people on 1,664 movies.
# Total number of ratings. Has to match the total number of cells (943*1664 = 1,569,152)
sum(table(as.vector(MovieLense@data)))## [1] 1569152Let’s now check what kind of ratings are contained in data matrix.
table(as.vector(MovieLense@data))##
## 0 1 2 3 4 5
## 1469760 6059 11307 27002 33947 21077The rating corresponding to 0 is actually a missing rating. Indeed, this is a sparse matrix with only about 99,000 actual ratings and rest 1.47 million cells with missing values.
9.4.1 Get some idea about the average ratings of the movies
Figure 9.4 shows the distribution of the average movies ratings. Although the distribution looks mostly bell-shaped, there are spikes at the extremes. This could be because these movies did not have enough ratings.
colMeans(MovieLense) %>%
tibble::enframe(name = "movie",
value = "movie_rating") %>%
ggplot(aes(movie_rating)) +
geom_histogram(color = "white") +
theme_minimal()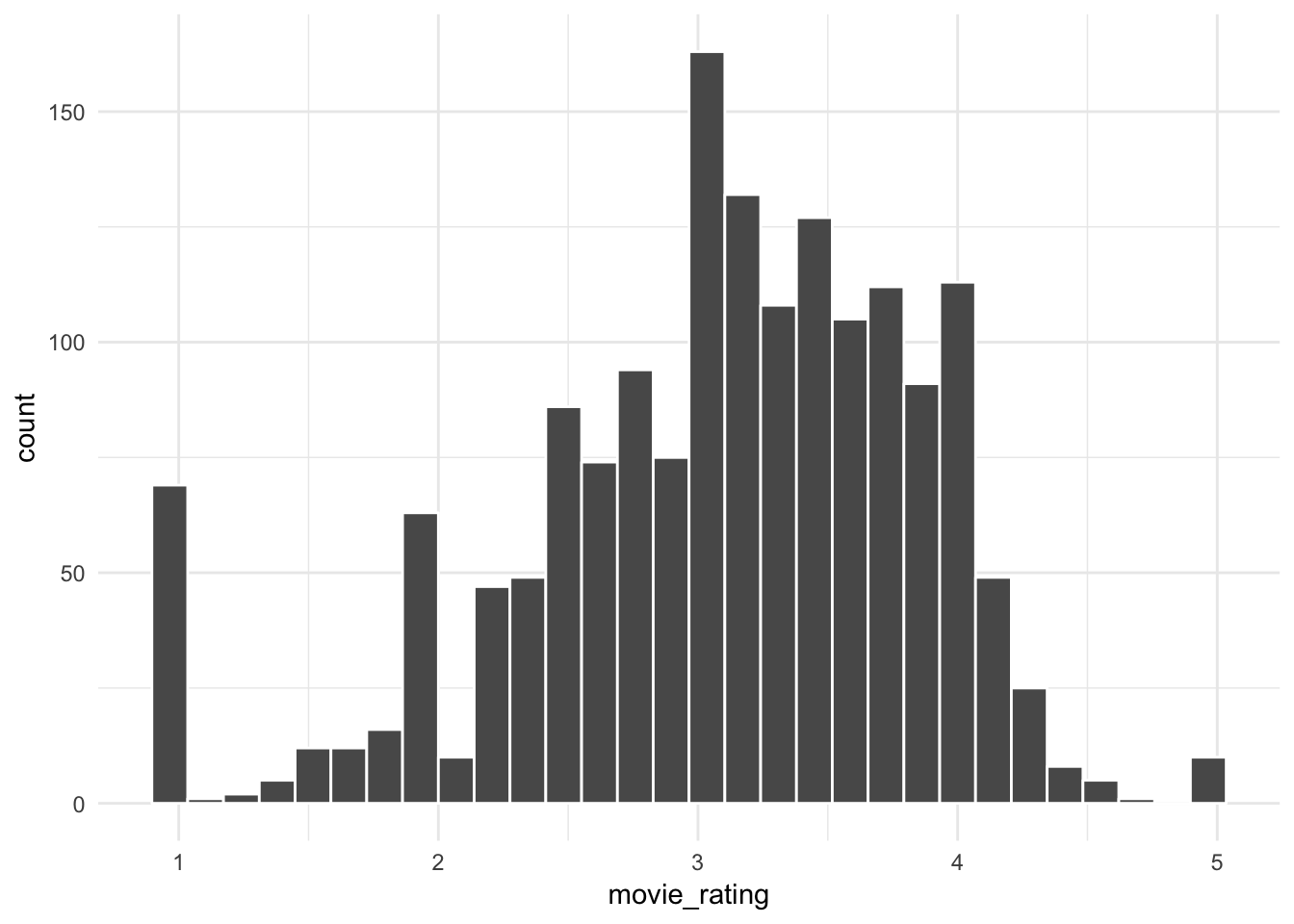
Figure 9.4: Average Movie Ratings
9.4.2 Get some idea about the total number of ratings by each user
Figure 9.5 shows the distribution of the user rating count. As expected, most users do not rate many movies. This is consistent with the power law in user rating counts in other domains.52
rowCounts(MovieLense) %>%
tibble::enframe(name = "user",
value = "rating_count") %>%
ggplot(aes(rating_count)) +
geom_histogram(color = "white") +
theme_minimal()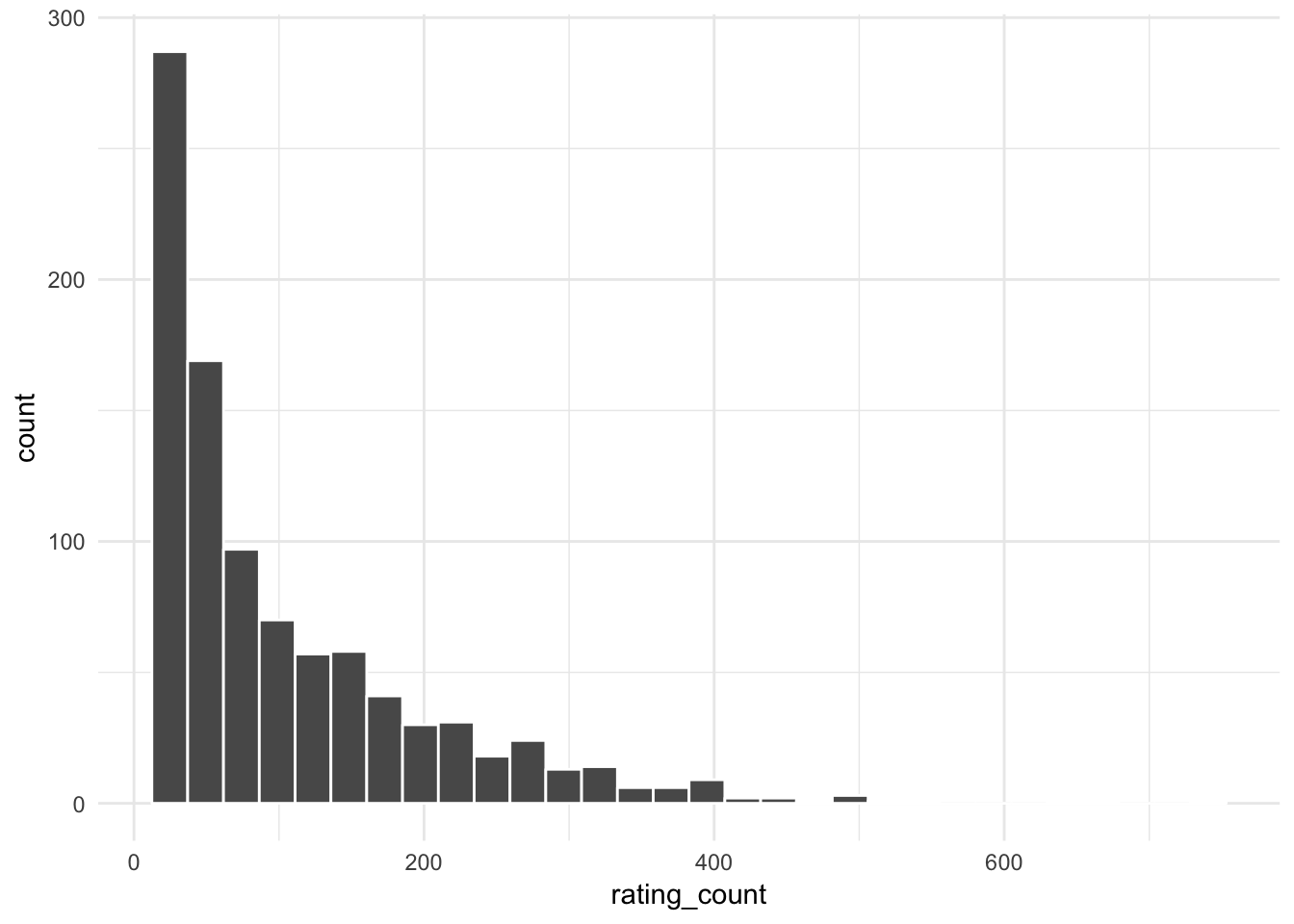
Figure 9.5: User Rating Count
For the analysis it might be a good idea to remove extreme movies and users. If a movie is rated by less than 50 users then we will drop it. If a user has rated fewer than 25 movies we will drop the user. Obviously these are subjective cutoffs so you can play around with other values. We will create a smaller matrix movie_small with these filters.
movie_small <- MovieLense[rowCounts(MovieLense) >= 25,
colCounts(MovieLense) >= 50]
movie_small## 816 x 601 rating matrix of class 'realRatingMatrix' with 80921 ratings.By using these cutoffs, we shrunk our data considerably. The resulting matrix is only about 31% of the original matrix.
sum(table(as.vector(movie_small@data))) /
sum(table(as.vector(MovieLense@data)))## [1] 0.3125357